 When did humans evolve, to its full extent, the capacity to create complex culture? We consider this question in a paper appearing in the May 7th issue of Scientific Reports. Here is a quick summary.
When did humans evolve, to its full extent, the capacity to create complex culture? We consider this question in a paper appearing in the May 7th issue of Scientific Reports. Here is a quick summary.
Human cultural capacity has been traditionally dated to about 30-40 thousands of years ago, based on an impressive cultural explosion in Europe around that time, leaving us such evidence as sophisticated stone tools and plenty of “art” (objects without any clear practical use), like the figurine depicted to the right, the lion man, and striking cave paintings.
There is a problem, though. If cultural capacity evolved in Europe 30-40 thousand years ago, how did all the human groups that where living outside Europe get it? We have no evidence of genetic flow from Europe to the rest of the world, through which the genes responsible for cultural capacity could have spread. It appears that humans must have had the capacity to create complex culture before they fragmented geographically over a large area. This conclusion, however, appears equally problematic because the first split between human populations is currently dated at about 170,000 years ago. Thus humans would have had the capacity for complex culture for more than 100,000 years before complex culture actually appeared. Although this appears unreasonable, we argue that things actually went this way.
First, we note that archaeologists have unearthed stone tools of complexity comparable to that of the European cultural explosion, but much older (more than 200,000 years old). We also note that other indicators of behavioral modernity appeared earlier than 170,000 years ago, such as genes believed to be important for language and the morphology of the speech apparatus.
Second, we summarize recent work in cultural evolutionary theory showing that cultural evolution is, in its initial stages, exceedingly slow. The reason is essentially that culture is a cumulative process: Complex culture can be created only by building on already existing culture. Thus in the initial stages of cultural evolution there was not enough raw material to be elaborated upon, and the creation of culture was slow. Additionally, human groups were at this time small and scattered over a large area, hence it is likely that cultural elements have been invented many times but disappeared (we make a couple of examples in the paper).
The bottom line is that there is no evidence inconsistent with an early origin of cultural capacity, and current understanding of cultural evolution shows that a long gap between the genetic evolution of the capacity and the actual invention is, in fact, quite expected.
And, we suggest in the paper, Neanderthals may have had the same cultural capacity as ourselves.
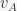 to stimulus
to stimulus  and
and  to
to  ) the associative strength for the compound
) the associative strength for the compound 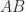 is, in the Rescorla & Wagner (1972) model:
is, in the Rescorla & Wagner (1972) model:

 is the proportion of stimulus elements in common between A and B. This makes it immediately apparent that
is the proportion of stimulus elements in common between A and B. This makes it immediately apparent that 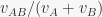 in Rescorla & Wagner (1972) ranges between 1/2 and 1, while in Pearce (1987) it ranges between 1/2 and 0.54. This results were previously known only in the special case
in Rescorla & Wagner (1972) ranges between 1/2 and 1, while in Pearce (1987) it ranges between 1/2 and 0.54. This results were previously known only in the special case 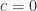 .
.

{kind=link}