While writing my previous JMP paper, On elemental and configural models of associative learning, I was also working out how the equivalence between elemental and configural models could be exploited for better analytical methods. My rationale for this research was that, in most cases, associative learning models are studied either intuitively or with computer simulation, making it difficult to establish general claims rigorously. After some time and fantastic input from reviewers and the editor, I am happy that Studying associative learning without solving learning equations came finally out over the Summer. This paper shows that the predictions of many models can be calculated analytically simply by solving systems of linear equations, which is much easier than trying to solve the models’ learning equations. For example, we can calculate that, in a simple summation experiment (training an associative strength to stimulus and to ) the associative strength for the compound is, in the Rescorla & Wagner (1972) model:
and in Pearce’s (1987) model:
where, in both cases, is the proportion of stimulus elements in common between A and B. This makes it immediately apparent that in Rescorla & Wagner (1972) ranges between 1/2 and 1, while in Pearce (1987) it ranges between 1/2 and 0.54. This results were previously known only in the special case .
I hope the method presented in the paper will be used also by others to derive new theoretical predictions and design new theory driven experiments!
Well, it seems I have not written here since two years ago! It has been a busy and exciting period, largely occupied by a book project that is looking at cognitive differences between humans and other animals. One of the by-products of this project is the title paper, a meta-analysis effort in collaboration with Johan Lind. In this paper, we offer a critical look at recent claims that birds, and in particular corvids, can “understand” properties of the physical world such as “light objects float, heavy objects sink,” and are able to use such knowledge to solve new problems. The performance of these birds in some tasks has been compared to that of 5-7 year old children.
The best way to understand the puzzles presented to the crows is to watch this video, from Jelbert et al. (2014) :
From the video, the performance of New Caledonian crows appears impressive. The results of our meta-analysis, however, are not supportive of the original claims. In summary, it seems that crows learn the correct behavior by trial-and-error as they perform the task. In almost all tasks, the birds start choosing one of the two options at chance, and only gradually they switch to the more functional option. The video shows the final stage of learning, rather than the initial random behavior.
We also compared the crow data with data from children, and we found clear differences. While younger children do not do well on most tasks, children aged 6 and older perform much, much better than birds, despite having received much less training.
There are one or two examples of tasks in which birds do well from the very beginning, as well as some tasks in which birds do not learn at all. In our paper, we argue that both occurrences can be understood based on established knowledge of animal learning, and especially associative learning.
A few weeks ago I had the good news that our paper on the comparator model of associative learning had been accepted in Psychological Review. This is my first published paper co-authored with by an undergraduate student, Ismet Ibadullaiev, which makes me even happier. The paper (I put up an unofficial copy on my Papers page) deals with a very interesting model of associative learning in which most of the interesting phenomena are generated as memories are retrieved, rather than when memory are stored as assumed by most mainstream theories of associative learning (e.g., the Rescorla-Wagner model and its derivatives).
Our conclusion, unfortunately, is that the theory makes a number of paradoxical predictions that are hard to reconcile with empirical data on learning. For example, it predicts that, in many cases, animals would not distinguish which of two stimuli is most associated with a reward (they do distinguish, of course), or that they should learn equally about faint and intense stimuli (in reality, animals learn preferentially about intense rather than faint stimuli).
These problems have been hard to recognize because the theory had been studied exclusively by intuition and computer simulation. Both are fine tools, but they do run into trouble. The predictions of comparator, as it turns out, vary greatly depending on the value of a few parameters, and our intuition is not well equipped to reason about the non-linear effects that abound in the theory. Simulations give us correct results, but only for the parameter combinations we simulate. We have been fortunate enough to realize that one could write down a formal mathematical solution to the theory. With this solution it became much easier to see the big picture and actually prove what the theory can or cannot do.
I enjoyed working with comparator theory because of its distinct flavor – as hinted above, it’s rather different from other learning models – and because of the many surprises we had while exploring its predictions. Although we found what appear to be serious flaws in the theory, these might be more in its mathematical implementation than in its core concepts. The ideas that memory retrieval is an important factor in associative learning, and that stimulus-stimulus associations are more important than other models acknowledge, may well be worth pursuing. But the formulae that translate these ideas into a testable model will surely need to be revised.
A new paper of mine just came out in the Journal of Mathematical Psychology. It considers an old issue that has traditionally split the field of associative learning, and that echoes various scientific disputes between holism and reductionism. The question is, when an animal learns about a stimulus, how is the stimulus endowed with the power to cause a response? Configural models of learning assume that a mental representation of the stimulus “as a whole” acquires associative strength (learning psychologists’ term for a stimulus’ power to cause a response), while elemental theories assume that the stimulus is fragmented in a number of small representation elements (say, shape, color, size, and so on), each of which carries some associative strength.
Long story short, it turns out that there is practically no difference in these two approaches. They amount to different bookkeeping of associative strength without this having necessarily any observable consequence. In fact, the main result of the paper is that, given some mild assumptions, for every configural model there is an equivalent elemental model – one that makes exactly the same predictions about animal learning – and, vice-versa, every elemental model has an equivalent configural model.
Thus there is no “better way” to think about how stimuli acquire associative strength, something that I expect will surprise some learning scholars. What I have personally most enjoyed discovering while working on this topic is that learning psychologists, and specifically John M. Pearce in this 1987 paper, have re-invented the formalism of kernel machines, a workhorse of machine learning and computer science since the 1960s. In fact, my proof of the equivalence of configural and elemental models is itself a re-discovery, in a much simpler setting, of the “kernel trick” of machine learning (see the previous link, and thanks to an anonymous reviewer for pointing this out).
Intriguingly, this is not the first time learning psychologists independently develop concepts that had been introduced in machine learning. Another remarkable case is Donald Blough‘s 1975 re-invention of the least mean square filter (or delta rule), a kind of error-correction learning that had been developed in 1960 to build self-regulating electronic circuits, and that Blough developed as a model of animal learning. I resist from speculating too much on whether this means that there is only one way to be intelligent – be it for animals or machines.
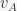 to stimulus
to stimulus  and
and  to
to  ) the associative strength for the compound
) the associative strength for the compound 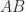 is, in the Rescorla & Wagner (1972) model:
is, in the Rescorla & Wagner (1972) model:

 is the proportion of stimulus elements in common between A and B. This makes it immediately apparent that
is the proportion of stimulus elements in common between A and B. This makes it immediately apparent that 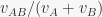 in Rescorla & Wagner (1972) ranges between 1/2 and 1, while in Pearce (1987) it ranges between 1/2 and 0.54. This results were previously known only in the special case
in Rescorla & Wagner (1972) ranges between 1/2 and 1, while in Pearce (1987) it ranges between 1/2 and 0.54. This results were previously known only in the special case 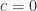 .
.